【SEO】搜尋引擎優化,懂這 3 點就夠了(上集)

SEO(Search Engine Optimization, 搜尋引擎優化),是透過搜尋引擎認可的運作規則、方法,在搜尋結果上取得排名,藉以獲得更多的自然流量 (Organic Traffic),爭取網站本身與品牌曝光。
如果只是要自己架網站或初步入門 SEO 這個坑,了解檢索、索引和排名機制就夠了 😼 😼
上集 - 了解搜尋引擎的運作,包含檢索、索引。
下集 - 搜尋引擎運作的最後一部分 - Ranking(排名機制) 以及進階演算法等。
目錄
搜尋時,你都在想什麼?
 Treasure Data CDP: 一站式數據整合、分析與應用平台
Treasure Data CDP: 一站式數據整合、分析與應用平台
如果想要在家煮咖啡的話,從你打開瀏覽器搜尋咖啡豆一直到送出訂單再宅配到你家,大概是以下的流程。
現今生活中,每天使用瀏覽器輸入關鍵字搜尋某個問題答案,從心裡認知需求到實際行動,會有這幾個節點:
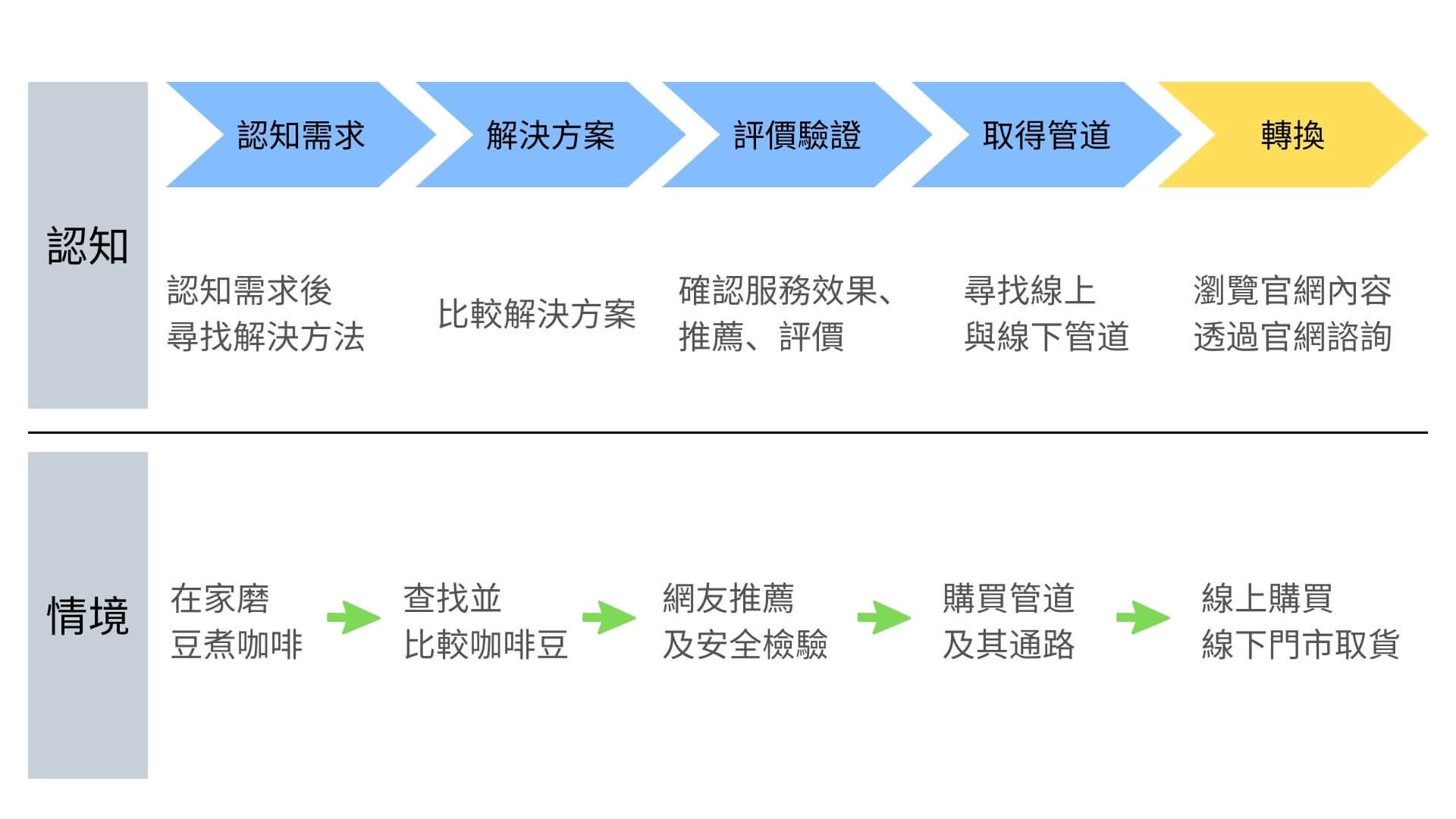
下面來看這過程的最重要的 3 個步驟,包含資料檢索、收錄資訊、結果曝光,其實還蠻有趣的 🧐 😆
什麼是 SEO(搜尋引擎優化)?
SEO(Search Engine Optimization, 搜尋引擎優化),是透過搜尋引擎認可的運作規則、方法,在搜尋結果上取得排名,藉以獲得更多的自然流量 (Organic Traffic), 爭取網站本身與品牌曝光。
平常要找一個問題的答案,你也是用 Chrome 嗎?
最常見的瀏覽器, 像是 Chrome, Edge, 這都是屬於瀏覽器,不是搜尋引擎,搜尋引擎是瀏覽器的底層運作系統,幫你找資料做檢索。
有大數據資料庫的搜尋引擎公司所開發的瀏覽器(Google Chrome, Microsoft Edge, Apple Safari)會抓取全世界的網頁內容,並提供給使用者「已排名的結果」,而使用者可透過瀏覽器的底層運作系統-搜尋引擎輸入關鍵字,並搜索出相對應的搜尋項目。
舉個例子,如果想要買 LV 精品, 以下是瀏覽器和搜尋引擎的差異:
瀏覽器用來呈現網頁,你直接在瀏覽器的 URL 輸入
https://tw.louisvuitton.com/zht-tw/homepage這個 Address, 它會跳轉到 LV TAIWAN 的頁面。Search Engine(搜尋引擎)透過瀏覽器查找跟關鍵字相關的網頁連結,輸入
Louis Vuitton, 顯示關於 LV 這個精品品牌的相關網頁連結結果。
下方是 Web Browser(網頁瀏覽器) 和 Search Engine(搜尋引擎) 的差異:
| Web Browser(網頁瀏覽器) | Search Engine(搜尋引擎) |
|---|---|
| 使用者使用的應用程式 | 將有價值的結果,顯示給 「搜尋消費者」的機器 |
| GUI(圖形化介面) | Search index(索引), Crawler(爬蟲), Search algorithm(演算法) |
| 沒有資料庫 | 有自己的資料庫 |
| 可安裝多個瀏覽器 | 不需安裝 |
| 例如:Chrome, Firefox, Naver | 例如:Google, Yahoo, Bing, DDG(DuckDuckGo) |
Search Engine(搜尋引擎)的運作
有初步的認識後,可以解釋為 SEO(Search Engine Optimization, 搜尋引擎優化) 是提供 「有價值的結果」 給 「消費者搜尋」 的機器。
接著就進一步認識,SEO 是如何做檢索和索引,以及爬蟲機器人的運作 💪🏾 💪🏾
-認識搜尋結果
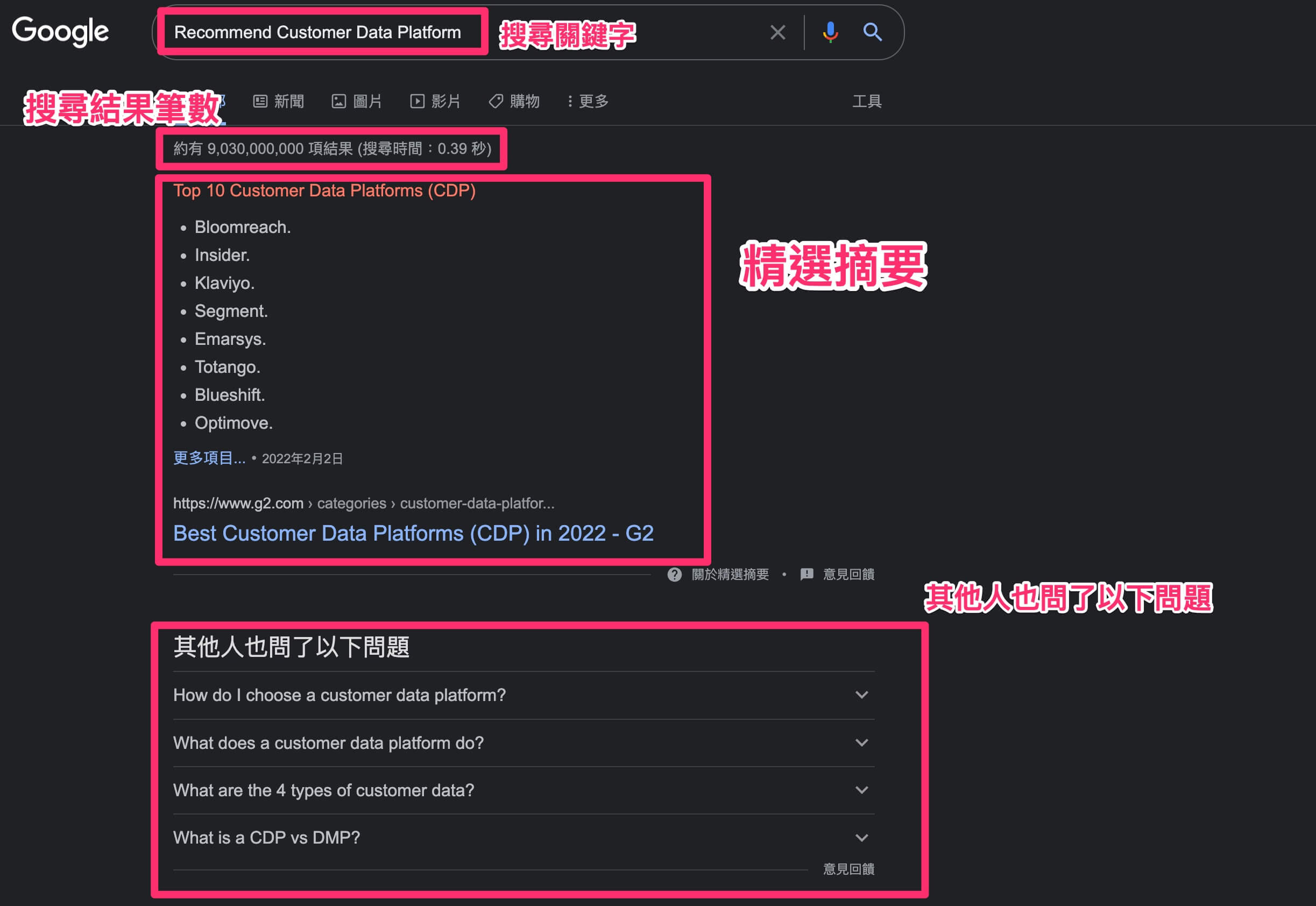
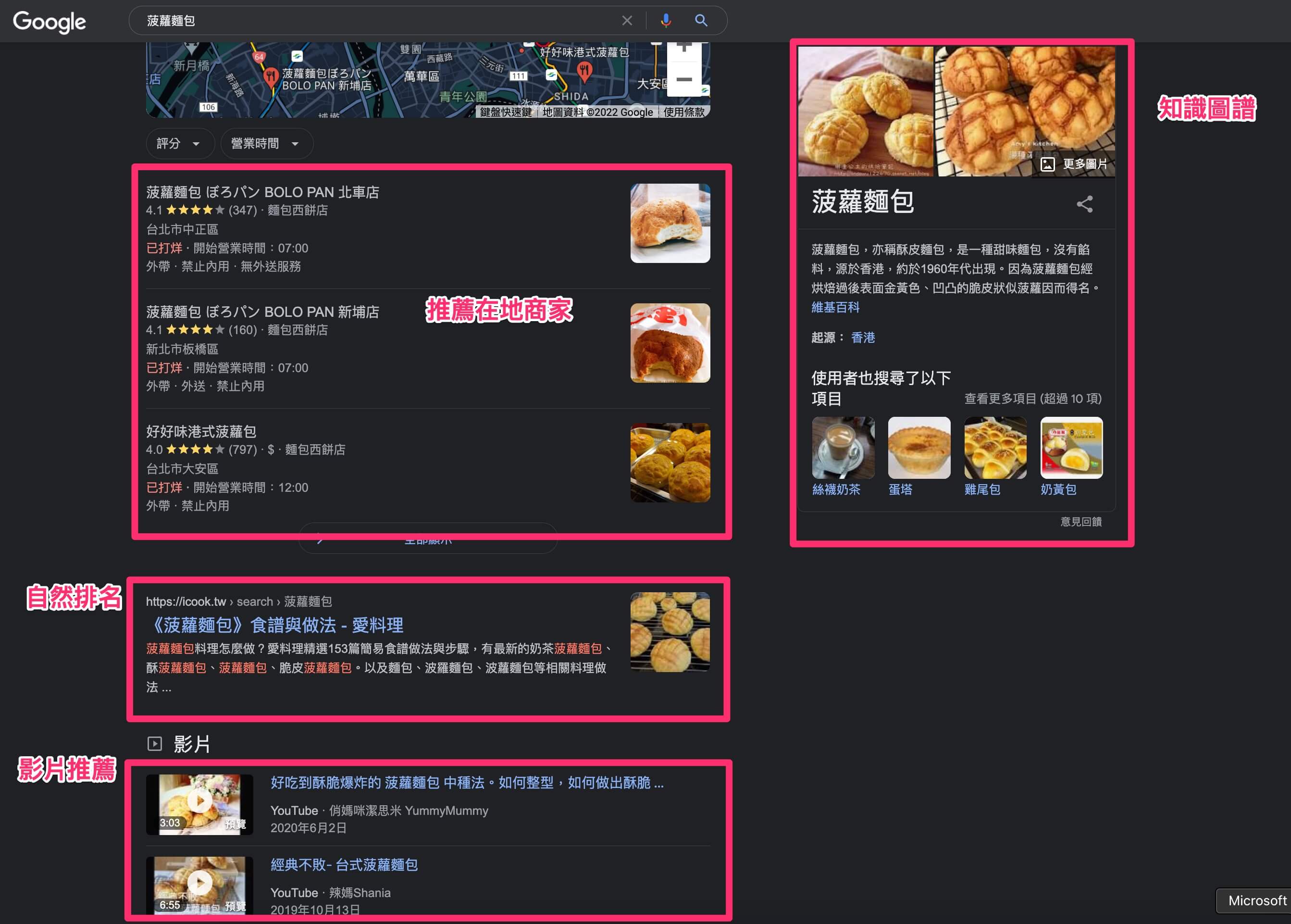
-運作方式
Search Engine 就是透過你在 Google Chrome 輸入的關鍵字,讓爬蟲機器人幫你從網路上尋找你想要得到的資訊答案,而幫你找資料做檢索的是 “搜尋引擎",而你做的動作就是 “搜尋",而SEO(search engine optimization, 搜尋引擎最佳化) 就是一連串改善並提升網站自然排名的行為(不包含廣告)。
Crawl(檢索, 檢查)
網路世界並沒有一個公司、機構,或任一地方儲存所有網站網頁資料,搜尋引擎用是用一個爬蟲機器人,簡稱 “搜尋引擎機器人” 或 “Crawlers(爬蟲)” ,透過 Crawl(檢索, 抓取) 的動作,爬行、蒐集已知及未知網頁的資料。業界通常會以 “爬資料” 來簡述這個過程。
各大搜尋引擎的爬蟲機器人都有不同的名字,最常見的 Google 是命名為 Googlebot.
爬蟲機器人認識網站裡的程式碼、文字、圖片等資料,以 Googlebot 來說,它看得懂的網頁元素,有這些:
- Meta tag (title, description…)
- HTML (h1, h2, p, a, …)
- 更多可識別資料
一個網站可能會被 Googlebot Desktop(桌上型設備) 和 Googlebot Mobile(行動裝置) 抓取。
在 2020 年 9 月, Google 宣布 所有網站都先以 Mobile 為優先索引。也就是當你從 Google Chrome 找資料時,爬蟲機器人會優先抓取網站有針對 手機裝置設計(RWD, Responsive Web Design 響應式設計) 過的網站。
Index(索引, 收藏)
爬蟲機器人去爬我們在瀏覽器輸入的關鍵字,接著就會將網站資料收錄到搜尋引擎的資料庫中,這就是收錄的過程。
但還有一個處理細節就是,Crawl(檢索)了網站及網頁之後,Google 將檢索到的內容進行分析、分類,它在背後去瞭解這個網頁的文字內容、圖片、影片及整個網頁的視覺排版,藉由這個分析來決定使用者搜尋相關內容時,網頁內容能顯示在搜尋結果頁中的哪個位置。
如何知道 Google 是否索引你的網頁?
在 Gooogle Chrome URL 輸入此代碼:site:欲查找網站 URL,就會看到以下這個結果:
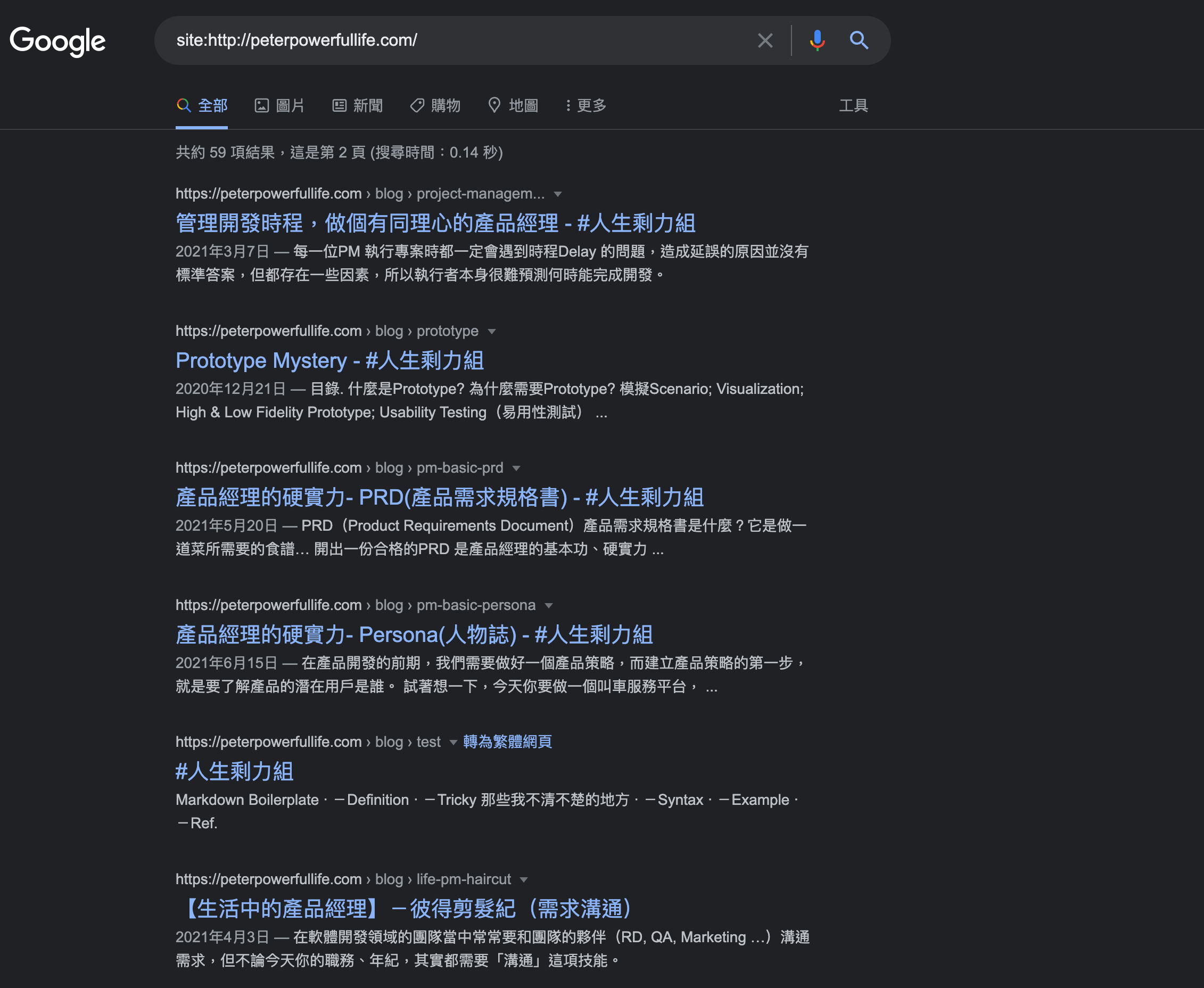
若網站沒有呈現在這個檢索頁面上,可能需要確認:
- 網站剛架設(等待 2 ~ 5 天觀察是否開始有收錄)
- 網站是否有 使用 noindex 禁止 Google 搜尋建立索引
- 網站是否有 Crawler directives(檢索機器人指令) 阻擋索引?
- 網站內部連結結構未有此網頁?
- 外部網站是否有連結至你的網頁?
如何知道 Googlebot 檢索看見的資料?
要讓網站能被夠被收錄,我們可以要求 Google 去檢索你的網站,透過 Google Search Console 線上工具 進行檢索與索引要求。
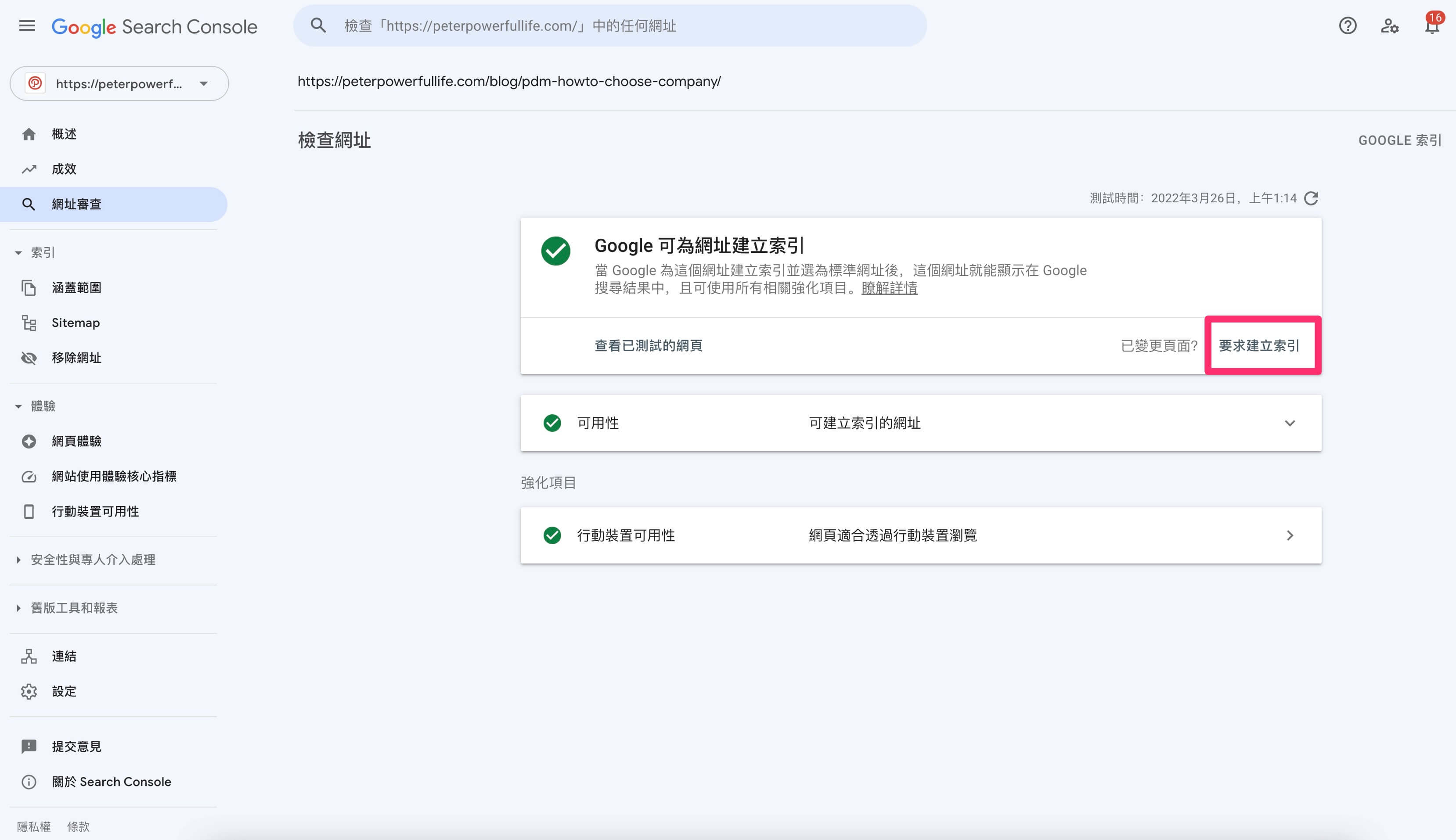
查看 Google 再檢索頁面後的結果,這個結果會顯示受測試網頁的「HTML」、「螢幕截圖」、及「更多資訊」,可以針對 Google 對這個網頁的分析去修正網頁內容。
以我寫過的 這篇文章 來做檢索,會得到以下的畫面:
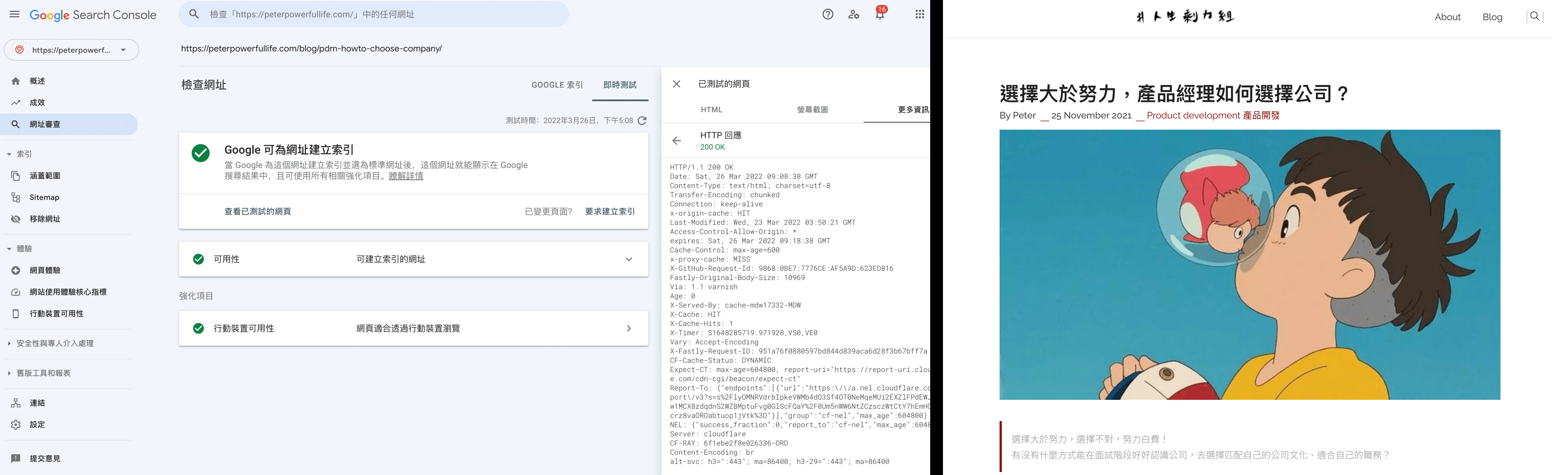
如何快速讓 Google 認識自己的網站?
- 入門 - 提交你的 Sitemap(網站索引地圖) 告訴 Google 我在這
- 進階 - 透過 robots.txt 檔案告訴 Google 該 / 不該 Crawl(檢索) 哪些頁面
- 進階 - 透過 Meta Robots 檔案阻擋 Google Index(收錄) 頁面
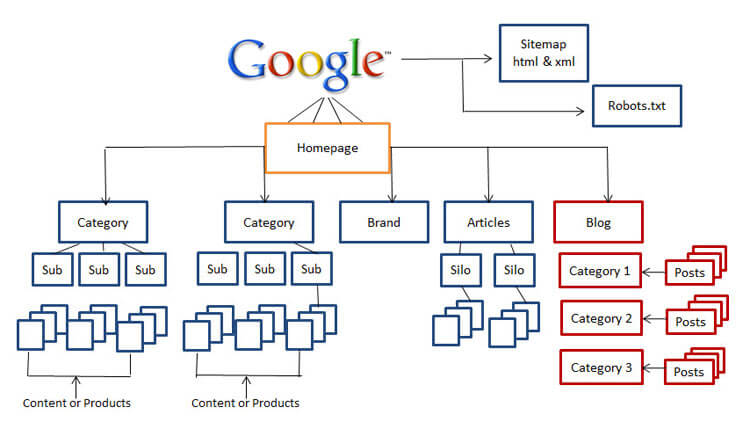
- 提交 Sitemap
Sitemap 告訴 Google 網站有哪些頁面,幫助 Google 了解你的網站,可以讓搜尋引擎追蹤你網站做了那些改變,同時更快的檢索、和建立索引。

Google 支援多種 Sitemap 格式,有 XML, RSS, mRSS and Atom 1.0 等多種方式,可以參考 Google 官方說明 唷。
最常見的是 XML(標記式語言) 格式,但無論是哪一種,它們都是給搜尋引擎查看的。如果我們要讓 Google Search Engine 認識你的網頁,那寫法就要遵循 Google 的規範,可以讓爬蟲造訪網站時,對於網站內的頁面一目暸然,並透過 Google Sitemap 報告 主動提交網站的 Sitemap, 讓 Google 知道要檢索網站中的哪些網頁,就能大大提高曝光機會。
如果發現有一個頁面遲遲找不到,可能就是沒有被收錄,這時就可以使用 Google Search Console 線上工具 審查,手動提交網頁來加快抓取速度。
這裡推薦 Sitemaps XML 語法格式,如果是前端工程師或是要建立自己的網站,真的要好好拜讀一下。
- 透過 robots.txt 讓爬蟲機器人只呈現你指定的頁面
有/無 robots.txt 檔案有什麼差異?
- 若無,Google 會繼續檢索全站。
- 若有,Google 會按照 robots.txt 指示檢索網站。
- 若 Google 在嘗試尋找 robots.txt 找不到,也無法確認網站是否為真的網站,Google 會放棄索引網站。
所以 Sitemap 和 robots.txt 的差別:
- 所有東西都在這,都給我收錄進去吧! Plz!!(Sitemap)
- 用一個範本檔案告訴 Google 你不要收錄這些資料啦!(robots.txt)
什麼時候會用到 robots.txt ?
據我對身邊朋友的簡單調查,通常純粹架站寫文章的 Blogger 都不會使用 robots.txt 去阻止搜尋引擎檢索網站。個人網站建議讓 Google 多爬點!因為這樣在 SEO 的曝光率才會比較高,更有辦法讓其他人在茫茫 Google 海中看到你。
不過,當你想要在已上線的網站新增一些功能,但這個功能還沒開發好、或是想要屏蔽平台會員的敏感個資,以 104 徵才平台 為例,會員的履歷、個人訊息、學歷等就是不允許被檢索的,這些情境就會需要用到 robots.txt 來限制。
robots.txt 檔案該建置在哪裡?
把建立好的 robots 的 .txt 檔案放到 根目錄,並在 robots.txt 檔案寫上你希望 / 不希望 Google 抓取的頁面路徑。
只要在查詢頁面後方加上 /robots.txt 就看得到了,來看看你我生活常用的產品:
Airbnb : https://www.airbnb.com.tw/robots.txt
Twitter : https://twitter.com/robots.txt
Netflix : https://www.netflix.com/robots.txt
Facebook : https://www.facebook.com/robots.txt
點上述網址,或是直接複製 URL 網址並貼到瀏覽器,就能看到 robots.txt 的內容,不過你只需要看幾個重點就好:
| robots.txt 檔案資訊 | 定義 |
|---|---|
| User-Agent | 爬蟲的名稱,像是 Googlebot, TelegramBot, Applebot等 |
| Allow | 允許爬蟲爬取的資料夾、頁面 |
| Disallow | 不允許爬蟲爬取的資料夾、頁面 |
不過,使用 Disallow 指令無法保證網頁不出現在搜尋結果中,因為 Google 可能還是會依據連結等外部資訊,認定網頁內容與使用者的查詢有所關聯,而在搜尋結果中顯示該網頁網址。 如果要明確禁止 Search Engine 為網頁建立索引,建議 使用 noindex 禁止 Google 搜尋建立索引 或 X-Robots-Tag HTTP。在這種情況下,不要透過 robots.txt 檔案直接封鎖網頁,因為搜尋引擎必須先檢索網頁,才有辦法發現標記並遵循指示。
- 可以 Crawl(檢索), 但不要 Index(收錄),就用 Meta Robots
啥?看到這是不是有點矇了 … 直接以情境來解釋吧!
如果你今天不希望幾個特殊頁面出現在 Search Engine, 像是忘記密碼、購物車、訂單等頁面,但是!這些頁面對 SEO 有所幫助,所以還是可以讓 Google 進行 Crawl(檢索),只是你不要 Index(收錄) 進去。
如何使用 Meta Robots ?
它的 HTML 標籤不算太複雜,若有這個需求,可以直接參照 Google SEO Docs
所有權在 Google 手上
Google 官方聲明 Meta Robots 以及 robots.txt 確實可以告訴 Google 你希望哪些頁面不要被檢索、索引,但他們只當作參考,並不保證 Search Engine 會完全遵照指示。 若搜尋引擎認為你的網站有很多反向連結、流量高、內容優質,那搜尋引擎還是會執意檢索、索引你的網站。
懂那麼多能做的還是有限 🥲 🥲
但也是有益處啦!若你也是 Blogger, 就可以優化網站的檢索及索引狀況,阻止特定頁面跟被抓到或是被索引。
若文章真的不想要給別人看的話,建議是直接不要上傳到個人網站上面,因為 robots.txt 只是一個軟性的警告,假設有意要害人的爬蟲,硬去爬 robots.txt 禁止的頁面,我們也是拿它沒辦法的。